
we’ll be designing a simple blog database schema, with functionality that’ll allow us to do CRUD and some other operations in postgres flavored sql, the end result will look like this: 

link to the diagram.
starring:
- db diagram, a very cool website that’ll allow u to design a schema and then export it into an image or into an SQL DDL script.
- dbeaver the Data Management Tool
- docker as the containarization tool for our DBMS container
- postgres as our DBMS
getting started
i’d be using docker to spin up a postgres container, see here.
1
docker container run -p 7878:5432 --name blogdummydb -e POSTGRES_PASSWORD=postgres postgres
after connecting, create a new database and call it blog or whatever u fancy:
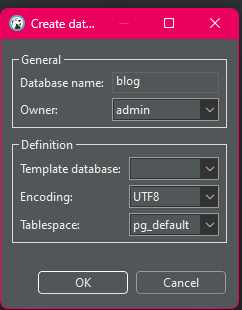
then click it and press CTR + ] to create a new script.
Architecture
Date time we will be using timestamptz which is the current date time in UTC, saving us the headache of messing with different timezones.
Keeping track of updatedAt for a record we can use one of these 2 strategies, either:
- creating a trigger which will fire up on insertion and update the field
- manually updating the field on insertion, which what we will be using
Primary key (id) type we’ll be using Serial which is an int in sequential order, for a couple of reasons:
- we don’t need uniqueness across services as we are not building a distributed system, so using a
UUIDwill hinder rather that help us, int is better for this case - indexing performance: cause of the compactness of an int the b-tree will not grow to be humongous, which will aid both the creation and scanning of the indexing. which in turn means less I/O resulting in a faster query.
- it’s faster to scan especially if you can have the index tree in ur RAM.
- cause
serialis sequential in nature it will mean better clustering on disk making queries and sequential scans more efficient.
post
- Slug will be in the form of a slug >.>, look here
- body is a text, which is unlimited, but since we are not exposing the ability to create a post to any user but the owner, we will ignore this issue.
user table
- password well assume a higher layer (like a backend) already hashed the password and it arrived ready to go.
- role: an Enum (‘USER’, ‘ADMIN’, ‘OWNER’)
likes will be 2 tables and it’s type is an enum of (UP, DOWN)
- one for the relation with
post - one for
comment
Comment
similar to reddit, this table will have a relation to itself to simulate deeeeeply nested replies.
it will also reference both the post id and the user’s id, we can replace the post relation to a generic entity if we wanted comments on another entity, like pictures for example.
functions
- a function will return a value specified
- Creation, Update -> id, cause the information provided is already in the front/back ends, thus no need to send and receive it again
- Deletion
- hard delete -> remove the entity and returns
trueon success - soft delete -> will flip
deleted/activeproperties and returntrue
- hard delete -> remove the entity and returns
- Querying will return a View which should be based on the needs of the application (has to be agreed on across the front - back - Db ends)
- on error will throw an exception to be caught and processed by a higher layer
Terminology and Relations
Terminology
- DDL : Data Definition Language, your
Create, Alterbasically any statement that has to do with messing with the structure - definition - of tables, schemas, users, etc - DML : Data Manipulation Language, your
insert, update, delete, basically the operations that Alters the data inside the table. - DCL : Data Control Language, as the name may imply it’s the statements that manages access rights for users or tables
GRANT <OPERATION> ON ECHEMA::<schema_name> TO <Username>DENY SELECT ON SCHEMA::schema_name TO username
- DQL : Data Query Language,
select, jointhe statements that get, aggregates data
Relations
- Post
posthave many to many relation withtagin form ofpost_tagjoin table.posthave many to one relation withcategoryin form ofcategory_idcolumn.posthave one to many relation withcommentin form ofpost_idinside thecommenttable.posthave one to many relation withpost_likesin form ofpost_idinside thepost_likestable.
- User
userhave one to many relation withcommentin form ofauthor_idinside thecommenttable.userhave one to many relation withpostin form ofauthor_idinside theposttable.userhave one to many relation withuser_rolesin form ofuser_idinside theuser_rolestable.userhave one to many relation withrefresh_tokenin form ofuser_idinside therefresh_tokentable.userhave one to many relation withpassword_reset_tokenin form ofuser_idinside thepassword_reset_tokentable.userhave one to many relation withpost_likesin form ofuser_idinside thepost_likestable.userhave one to many relation withcomment_likesin form ofuser_idinside thecomment_likestable.
- Comment
commentis a self referencing table, we’ll be querying it recursively; Known as CommonTableExpressions CTEs.
- Reaction tables
post_likesrepresents thepostreaction by relateduserscomment_likesrepresents thecommentreaction by relatedusers
Begin !
we’ll start by creating the post table:
this way it will be created as [current selected schema].post, so be weary of it.
post
1
2
3
4
5
6
7
8
9
10
11
12
CREATE TABLE "post" (
"id" serial PRIMARY KEY,
"title" varchar UNIQUE NOT NULL,
"slug" varchar UNIQUE NOT NULL,
"body" text NOT NULL,
"author_id" integer,
"published" boolean NOT NULL DEFAULT true,
"publish_time" timestamptz,
"created_at" timestamptz DEFAULT (now()),
"updated_at" timestamptz
);
ALTER TABLE "post" ADD FOREIGN KEY ("author_id") REFERENCES "user" ("id");
explanation of the types:
- Serial : is an int in order. you can tell it where to start
- Varchar : is just text, limited in width / size.
- text : i believe in postgres this is not limited, you can check the length to limit it if it’s not.
- boolean : could wither be True or False or null but explictly added that it cannot be null via: Not Null constraint
- it has the same size of
1bitas an int, using it to me is easier to understand what it’s purpose at a glance, unlike an int. - default : signifies what the colum’s value will be sat as if we don’t specify a value for it
- it has the same size of
- timestamptz : this stores the current timestamp with the date in UTC.
- FOREIGN KEY : signifies a relation to another table’s field of the same type, in this case the user’s table id
- Alter : is a DDL statement that modifies the table and ADDs a
FOREIGN KEYconstraint to theauthor_idcolumn
test it
test it by selecting a row: select * from post; the * gives us all the values, typically this kind of select is bad performance wise cause the database will scan the entire page on disk in order to give you all the rows inside the table. an explain analyze select * from post has no cost if u just wanna know the count of rows;
we can now try to insert a record -each value has to be in the order of the columns you selected-:
1
2
3
4
5
6
7
8
9
10
insert into "post" (
title, slug, body, published, updated_at
)
values (
'first post',
'first-post',
'markdown should be here',
true,
now()
);
after selecting * you would get this: 
both the author_id and published_time are null, cause we neither provided a value nor gave them a default one, unlike the created_at which defaults to the current time. now() or CURRENT_TIMESTAMP.
tag
now, let’s add in the tag table and it’s join table
1
2
3
4
5
6
7
8
9
10
11
12
13
CREATE TABLE "tag" (
"id" serial PRIMARY KEY,
"name" varchar UNIQUE NOT NULL,
"created_at" timestamptz DEFAULT (now()),
"updated_at" timestamptz
);
CREATE TABLE "post_tag" (
"post_id" integer NOT NULL,
"tag_id" integer NOT NULL,
CONSTRAINT "PK_post_tag" PRIMARY KEY ("post_id", "tag_id"),
constraint "FK_post_tag_blog_post_post_id" FOREIGN KEY (post_id) REFERENCES post(id) ON DELETE CASCADE,
CONSTRAINT "FK_post_tag_tag_tag_id" FOREIGN KEY (tag_id) REFERENCES tag(id) ON DELETE CASCADE
);
in here we need to set relations, the tag table and the post table has many to one relation with post_tag join table, and to create an id for it, the id should be made up from the foreign keys
- creating the key:
- inside the DDL :
Primary key('post_id', 'tag_id),
- inside the DDL :
we can either add in the constraint inside the DDL of the table, or Alter the table after the fact:
- adding a relation:
ALTER TABLE "post_tag" ADD FOREIGN KEY ("post_id") REFERENCES "post" ("id") ON DELETE CASCADE;
let’s create a new tag and add it to the post we have:
1
2
insert into tag(name, created_at, updated_at)
values ('sql', now(), now()) returning id;
to capture the returned id you need to declare a variable.
now grab the id and insert it with the post id we already have and insert them into post_tag table creating a relation between them
1
2
insert into post_tag (post_id, tag_id)
values (1, 1);
joins
we have a relation now, cool and all but how can we use it ?
with joins !
a join is a DQL statements that joins 2 tables via a condition.
1
2
3
4
5
6
7
SELECT [columns] FROM [first table]
[join direction] JOIN [second table, or the same table]
ON [a condition that related both tables]
[another join, up to N number of them i believe]
SELECT TA.column FROM Table_A TA
JOIN Table_B TB on TA.Id = TB.table_a_id;
when u join a table and give it a shorter name like
Table_A TA,Table_B TBis called an alias, it is used to shorten the table name.
There are 7 directions:
- inner (the default if no direction is specified) : returns only the rows that match in both tables
- Left : returns all rows from the left table and the matching rows from the right table and a null if there’s no match
- Right : returns all rows from the right table and the matching rows from the left table and a null if there’s no match
- Self : is when you join a table with itself (like a comment with a reply) or (employee with manager)
- cross : returns the cartesian product of the two tables basically all rows from both sides without any condition
- useful when u want let’s say the
idfield from both theuserandposttables without relations.select "u".id "user id", "p".id "post id" from "post" p cross join "user" u ; ![cross_join]()
- useful when u want let’s say the
- full : gets all the rows from both tables even if there’s no match
- natural: joins both tables based on the column names matching
test it
1
2
3
4
5
6
7
8
select
p.title as "Post Title",
t."name" as "Tag Name"
from post p
join
post_tag pt on p.id = pt.post_id
join
tag t on t.id = pt.tag_id;
which will give us: 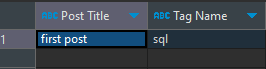 .
.
now, when we insert a new post we’d like to do some operations, like creating a relation with a user, tag(s), category(s), transform the title into a slug, doing this manually every time is neither efficient nor fun and it’s error prone.
we’ll abstract all that in a function or procedures where appropriate!
Functions
here the fun begins !
a function differs from a procedure in that it has to return a value, commonly a VIEW which is a virtual table made from the result of the function. while a stored procedure will not return anything.
anatomy of a function:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
create or replace function [function name] ([param_A param_A_type,... ,param_N param_N_type ])
returns [return type] <- for normal return types
returns table ( [ table definition ] ) <- for table return type
as
$$
declare
[variables you may need in the body of the function]
begin
[the body of the function i:e what u wanna do]
end;
$$ language plpgsql; -- not really sure what this is
ex:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
create function create_post(title varchar(255), body text) -- fn declaration
-- the return type, in this cause a table or a "view"
returns table (title_ varchar(255), createdAt_ timestamptz) as $$
declare
-- these 2 are variable we use in the body of the function
post_slug varchar; -- for use for the creation of a slug
new_post_id int; -- to get the post id in order to return the values
begin -- denotes the beginning of the transaction
-- this will "sanitize" the title and make it into a slug
post_slug := regexp_replace(
regexp_replace(lower(trim(title)), '[^a-zA-Z0-9]+', '-', 'g'),
'-$',
''
);
insert into post
(title, slug, body, updatedAt)
values
(
title,
post_slug,
body,
now() -- instead of creating a separate trigger, this is all we need
)
returning id into new_post_id; -- this way you can get the new id
-- our returned "view
return query
select
p.slug as slug_,
p.createdAt as createdAt_
from post p
where
p.id = new_post_id;
end; -- commit !
$$ language plpgsql
before we continue, we’ll add in all the other tables, you can go to db diagram and export it to ur DBMS of choice, or get the .sql file for postgres.
create user function
firstly we need to be able to add in a user, to that we require a username, an email, a hashed password and we also need to create a role for it as well as generate a verification token, so they can verify.
this translate into a function that would take in username, an email, a hashed password and will return a verification token.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
create or replace function fn_create_user(username varchar(128), email varchar(128), hashed_password varchar(255))
returns text as
$$
declare new_id int;
declare new_verification_token text;
begin
insert into "user" ("username", "email", "password")
values (username, email, hashed_password) returning id into new_id;
insert into user_roles("user_id", "role")
values (new_id, 'USER');
select MD5('not sure where to put this . . .') into new_verification_token;
update "user"
set
verification_token = new_verification_token,
updated_at = now()
where "user"."id" = new_id;
return new_verification_token;
end
$$ language plpgsql;
this is the happy path, what about if something went wrong then what ?
we can return an exception to whomever is trying to call the function, there are multiple levels of it but we will use the highest exception which will halt the execution of the transaction.
syntax is:
1
2
3
4
5
6
7
8
9
10
11
12
...
BEGIN
normal flow.
return something;
EXCEPTION
when [exception] then
-- do stuff
RAISE [EXCEPTION LEVEL] ['MESSAGE'] ;
END;
...
exception levels from lowest to highest: log, info, debug, warning, notice and exception which halts the transaction.
we can add it into our function just before the end block.
1
2
3
exception
when others then
raise exception 'could not create new user';
now we can query the user’s table to see the newly created user:
1
2
select u.username, u.email, u.verification_token, u.verified, ur."role"
from "user" u join "user_roles" ur on u.id = ur.user_id;
create post function
since we created a user, let’s implement a create post function:
remember, a post has a category and a lot of tags, also we need to set the published flag depending on a condition, we’ll also be creating/adding the category provided and the same with the tags.
the tags will be taken in as a comma delimitated string: ‘tag1, tag2, …’
since you would have the data in the front end you would just append it to the ds you’re using, and the cache for the backend, so it would only returns the id of it
syntax of if
1
2
3
4
5
if [condition] then
else
end if ;
syntax of for loop
1
2
3
for [variable] in [structure] loop
end loop;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
create or replace function fn_create_post(user_id int, title varchar(128), body text,published boolean, tags text, category varchar(64))
returns int as
$$
DECLARE
new_post_id int;
post_slug varchar(64);
tag_name varchar(64);
tag_slug varchar(64);
cat_name varchar(64);
cat_slug varchar(64);
cat_id int;
BEGIN
-- create the post slug
post_slug := regexp_replace(
regexp_replace(lower(trim(title)), '[^a-zA-Z0-9]+', '-', 'g'),
'-$',
''
);
-- get the new id
INSERT INTO "post" ("title", "body", "slug", "published", "updated_at", "author_id")
VALUES (title, body, post_slug, published, now(), user_id)
RETURNING id INTO new_post_id;
-- set pub time
IF published THEN
UPDATE "post"
SET publish_time = now()
WHERE id = new_post_id;
END IF;
-- create tags and set their relation
FOR tag_name IN SELECT unnest(string_to_array(tags, ',')) LOOP
tag_name := lower(trim(tag_name));
tag_slug := regexp_replace(
regexp_replace(lower(trim(tag_name)), '[^a-zA-Z0-9]+', '-', 'g'),
'-$',
''
);
INSERT INTO tag (name, slug)
VALUES (tag_name, tag_slug)
ON CONFLICT (name) DO NOTHING; -- the name is unique, so if there's a conflict on creating a new record this will ignore the error that'll occur
INSERT INTO post_tag (post_id, tag_id)
SELECT new_post_id, id
FROM tag
WHERE name = tag_name;
END LOOP;
-- create category's name, slug
cat_name := lower(trim(category));
cat_slug := regexp_replace(
regexp_replace(lower(trim(cat_name)), '[^a-zA-Z0-9]+', '-', 'g'),
'-$',
''
);
INSERT INTO category (name, slug)
VALUES (cat_name, cat_slug)
ON CONFLICT (name) DO NOTHING; -- same with the tag one
-- set the relation
UPDATE "post"
set category_id = (select id from category where "name" = cat_name)
where post.id = new_post_id;
return new_post_id;
EXCEPTION
WHEN others THEN -- all errors, similar to Exception in .net
RAISE LOG 'Error: %', SQLERRM;
RAISE EXCEPTION 'Could not create a new post: %', SQLERRM;
end
$$ language plpgsql;
this was long, lets test it and see:
1
2
3
4
5
6
7
select
p.id, p.title, p.slug, u.username, c.name "Category name", c.slug "Category slug"
from "post" p
join post_tag pt on p.id = pt.post_id
join tag t on pt.tag_id = t.id
join category c on p.category_id = c.id
join "user" u on p.author_id = u.id;
this would return to us 2 rows cause we added 2 tags, 
to grab them we’d aggregate them using json one of the reasons i love postgres
1
2
3
4
5
6
7
8
9
select
p.id, p.title, p.slug, u.username, c.name "Category name", c.slug "Category slug",
(
select json_agg(json_build_object('tag name', t.name, 'tag slug', t.slug) )
from tag t join post_tag pt on pt.tag_id = t.id join "post" p on p.id = pt.post_id where pt.post_id = p.id
) as tags
from "post" p
join category c on p.category_id = c.id
join "user" u on p.author_id = u.id;
this will give us the tags as a json object, personally i think this is simple to use on the higher layer (backend)

comment create function
now, let’s add in the comments creation function.
for this we’d need: the comment body, the user and post id’s and if a parent comment id if this is a reply, the return type will be the id of the new comment.
the
parent_idcolumn can benull, so if this comment is not a reply we can providenullinstead of anid.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
create or replace function fn_Create_comment(body text, post_id int, user_id int, parent_id int)
returns int as
$$
declare
new_comment_id int;
begin
insert into comment ("body", "post_id", "author_id", "parent_id")
values (body, post_id, user_id, parent_id)
returning id into new_comment_id;
return new_comment_id;
EXCEPTION
WHEN others THEN
RAISE LOG 'Error: %', SQLERRM;
RAISE EXCEPTION 'Could not create a new comment: %', SQLERRM;
end;
$$ language plpgsql;
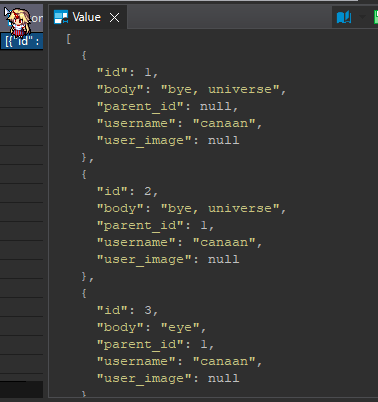
now, create a comment select * from fn_create_comment('bye, universe', 7, 7, null); feel free to create a bunch!
after which 
aggregating them in a beautiful form/table is the job of the front end!
now let’s expand the post query from earlier to include the comments too
1
2
3
4
5
6
7
8
9
10
11
12
13
select
p.id, p.title, p.slug, u.username, c.name "Category name", c.slug "Category slug",
(
select json_agg(json_build_object('tag_name', t.name, 'tag_slug', t.slug) )
from tag t join post_tag pt on pt.tag_id = t.id join "post" p on p.id = pt.post_id where pt.post_id = p.id
) as tags,
(
select json_agg(json_build_object('id', c.id, 'body', c.body, 'parent_id', c.parent_id, 'username', u.username,'user_image', u.profile_picture ))
from "comment" c join "user" u on c.author_id = u.id
) as comments
from "post" p
join category c on p.category_id = c.id
join "user" u on p.author_id = u.id;
this will give us the same result as before but the the comments we’ve created, remember there’s no need unless u want to self join to order the comments with their reply, we give the parent_id to the front end and it’ll take care of this, our responsibility ends with providing the needed info.
likes upsert function
finally we’ll implement the liking/disliking system
i wanted a generic table for all liking needs, but that makes querying the table a pain, so i settled on a table for each entity that will be liked
we have 2 tables, a comments_likes and a post_likes, both use an enum of either (‘UP’,’DOWN’)
the functions we’ll create will have double duty of creating or updating upserting a like and will return the new amount of reaction be it UP or DOWN, both of them are practically the same with the only difference being the table name, so only one is implemented here.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
CREATE OR REPLACE FUNCTION fn_upsert_comment_likes(
user_id_ INT,
comment_id_ INT,
reaction like_type -- this is the enum we created
) RETURNS INT AS
$$
declare
amount int;
BEGIN
IF EXISTS (
SELECT 1 FROM "comment_likes" cl
WHERE cl."user_id" = user_id_
AND cl."comment_id" = comment_id_
AND type = reaction
)
THEN
DELETE FROM comment_likes WHERE "user_id" = user_id_ AND "comment_id" = comment_id_ AND type = reaction;
ELSE
DELETE FROM comment_likes WHERE "user_id" = user_id_ AND "comment_id" = comment_id_;
INSERT INTO comment_likes ("user_id", "comment_id", type)
VALUES (user_id_, comment_id_, reaction);
END IF;
SELECT COUNT(*) into amount
FROM comment_likes cl
WHERE cl."user_id" = user_id_ AND cl."comment_id" = comment_id_ and type = reaction;
return amount;
EXCEPTION
WHEN others THEN -- all errors, similar to Exception in .net
RAISE LOG 'Error: %', SQLERRM;
RAISE EXCEPTION 'Could not update the reaction: %', SQLERRM;
END;
$$
LANGUAGE plpgsql;
run it like this: select * from fn_upsert_comment_likes(7, 2, 'UP'); and again to see that it resets the reaction
run it again but instead of UP the second time use DOWN then select it select * from comment_likes where user_id=7; it will correctly save the DOWN

now to add it in our aggregate query!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
select
p.id, p.title, p.slug, u.username, c.name "Category name", c.slug "Category slug",
(
select json_agg(json_build_object('tag_name', t.name, 'tag_slug', t.slug) )
from tag t join post_tag pt on pt.tag_id = t.id join "post" p on p.id = pt.post_id where pt.post_id = p.id
) as tags,
(
select json_agg(
json_build_object(
'id', c.id,
'body', c.body,
'likes',(select count(*) from comment_likes cl where cl.comment_id = c.id and type='UP') ,
'dislikes', (select count(*) from comment_likes cl where cl.comment_id = c.id and type='DOWN')
'parent_id', c.parent_id,
'username', u.username,
'user_image', u.profile_picture
)
)
from "comment" c join "user" u on c.author_id = u.id
) as comments
from "post" p
join category c on p.category_id = c.id
join "user" u on p.author_id = u.id;
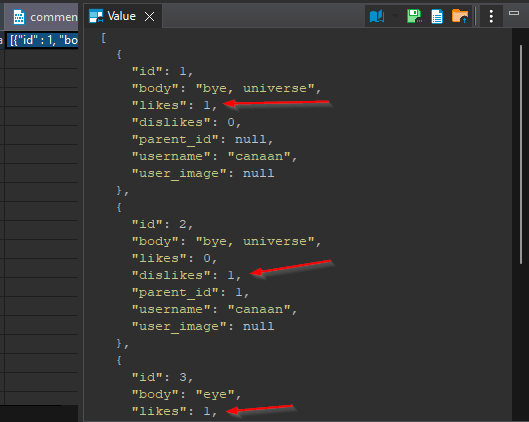
closing
with this we’ve covered the more interesting operation,the Read functions will return a view table that should fit your models, they would look like something like this or a bit less complicated
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
select
p.id, p.title, p.slug, u.username, c.name "Category name", c.slug "Category slug",
(
select json_agg(json_build_object('tag_name', t.name, 'tag_slug', t.slug) )
from tag t join post_tag pt on pt.tag_id = t.id join "post" p on p.id = pt.post_id where pt.post_id = p.id
) as tags,
(
select json_agg(
json_build_object(
'id', c.id,
'body', c.body,
'likes',(select count(*) from comment_likes cl where cl.comment_id = c.id and type='UP') ,
'dislikes', (select count(*) from comment_likes cl where cl.comment_id = c.id and type='DOWN'),
'parent_id', c.parent_id,
'username', u.username,
'user_image', u.profile_picture
)
)
from "comment" c join "user" u on c.author_id = u.id
) as comments
from "post" p
join category c on p.category_id = c.id
join "user" u on p.author_id = u.id;
the reset of the functions are super samey so i’ve chosen not to include them here.
you may also want to create a custom docker container for your database, you’d have to do something like this:
- a creation script, that would create your database and tables,
creation_epic.sqlfor example - a functions script, which will create the functions and procedures you want,
functional_epic.sql - in your
Dockerfile:
1
2
3
4
5
FROM postgres:[version]
COPY ./creation_epic.sql docker/-entrypoint-initdb.d/
COPY ./functional_epic.sql docker/-entrypoint-initdb.d/
expose [port]
- the image would auto populate according to the epics !